workspace/backend
Redis Basic - overview
HwangJerry
2023. 9. 11. 10:14
Redis 소개
- REmote DIctionary Server
- Remote : 각각의 서버의 로컬에 존재하는 것이 아닌, 다수의 서버가 공통적으로 사용할 수 있도록 원격에 존재
- Dictionary : 해시맵과 같이 key-value 형태로 구성되어 있어, 자료를 조회할 때 상수 시간 O(1) 으로 실행
- 즉, 레디스는 다수의 서버가 공유할 수 있는 해시 테이블 데이터베이스
- 데이터베이스 total ranking : 6위, key-value DB ranking 1위
주요 특징
- in memory : 모든 데이터를 RAM에 저장 (백업/스냅샷 제외)
- single threaded : 단일 thread에서 모든 task를 처리한다. 멀티 스레드는 프로그램의 복잡도를 증가시킴. 레디스는 단순한 디자인을 적용하여 뛰어난 성능을 자랑하고, 잘 사용하면 사이드 이펙트가 거의 없다.
- cluster mode : 다중 노드에 데이터를 분산 저장하여 안정성 & 고가용성 제공
- persistence : RDB (Redis database) + AOF (Append Only file) 통해 영속성 옵션 제공
- Pub/Sub : pub/sub 패턴을 지원하여 손쉬운 어플리케이션 개발 (e.g 실시간 채팅, 알림 등)
Persistence
레디스는 주로 캐시로 사용되기 때문에 손실되어도 무방한 데이터를 저장하는 게 기본입니다. 하지만 현실적으로 결국은 서비스를 운영하는 데에 필요한 데이터의 일부가 레디스를 거치게 되기 때문에, 레디스 데이터가 손실될 경우 서비스가 느려지거나 서버에 장애가 발생하게 될 수 있습니다.
따라서 레디스는 안정적인 캐시 서버 운영을 위해 데이터 손실을 방지하기 위한 옵션으로 ssd와 같은 영구저장 장치를 활용하여 데이터를 저장하기도 합니다. 이는 영속성 옵션이라고 부르며, 아래 두 가지가 있습니다.
✅RDB (Redis Database)
📌 point-in-time snapshot, 즉 특정 시점에 스냅샷을 생성해두는 기술입니다. (백업 파일을 생성해 둔다고 이해하면 됩니다.) → 재난 복구(disaster recovery) 또는 복제에 주로 사용
📌 동일한 데이터를 가진 캐시를 복제할 때 주로 사용됩니다. 특정 시점에서 스냅샷을 만들고, 그 다음 스냅샷을 생성하기 이전에 레디스 데이터가 유실되면 그 동안의 데이터는 유실될 수 있습니다. 스냅샷 생성 중에는 레디스 서버의 성능 저하가 발생할 수 있어, 스냅샷 생성 중에는 클라이언트 요청 처리에 지연이 발생할 수 있습니다.
✅AOF (append on file)
📌 Redis에 적용되는 write 작업을 모두 log로 저장하는 기술을 의미합니다. 데이터 유실의 위험이 적지만, 재난 복구시 log를 따라 write 작업을 다시 적용하기 때문에 RDB 방식보다 복원하는 속도가 느립니다.
⇒ 레디스에서는 영속성 옵션을 사용하지 않거나, 두 가지 옵션중 하나를 사용하거나, 두 가지 영속성 옵션을 모두 사용(RDB + AOF)하는 방식으로 사용됩니다.
장점
- 높은 성능 : 모든 데이터를 메모리에 저장하기 때문에 매우 빠른 읽기/쓰기 속도 보장
- data type 지원 : redis에서 지원하는 data type을 잘 활용하여 다양한 기능 구현
- 클라이언트 라이브러리 지원 : python, java, js 등 다양한 언어로 작성된 클라이언트 라이브러리 지원 - 백엔드와 연동이 쉬움
- 다양한 사례 / 강한 커뮤니티 : redis를 활용하여 비슷한 문제를 해결한 사례가 많고, 커뮤니티 도움을 받기 쉬움
사용 사례
- caching(가장 빈번함) : 임시 비밀번호(One-Time password) / 로그인 세션 (Session)
- rate limiter : fixed-window / sliding-window rate limiter (비율 계산기) - 서버에서 특정 api에 대한 요청 회수를 제한하기 위한 기술
- message broker : 레디스의 Lists나 Streams(?)같은 데이터 타입을 활용하여 메시지 브로커를 구현 가능. 이를 통해 다양한 서비스 간 커플링을 줄일 수 있음. (메시지 큐 역할)
- 실시간 분석 / 계산 : 순위표(rank / leaderboard) , 반경 탐색(geofencing), q방문자 수 계산(visitors count)
- 실시간 채팅 : pub/sub 패턴
Caching
redis의 활용 사례로 가장 많이 이용되는 Caching에 대해 간단히 알아봅시다.
- 개념
- 캐싱은 데이터를 빠르게 읽고 처리하기 위해 임시로 저장하는 기술
- 이미 계산된 값을 임시로 저장해 둠으로써, 동일한 계산이나 요청 발생 시 다시 계산하지 않고 저장된 값을 바로 사용
- 캐시(Cache) = 임시 저장소
- 사용 사례
- CPU 캐시 : CPU와 RAM 사이에 속도 차이를 비교하면, CPU가 압도적으로 빠릅니다. CPU와 RAM의 속도 차이로 발생하는 지연(CPU가 RAM을 기다리는 시간)을 줄이기 위해 L1, L2, L3 캐시 사용
- 웹 브라우저 캐싱 : 웹 브라우저가 웹 페이지 데이터를 로컬 저장소에 저장하여 해당 페이지 재방문시 사용
- DNS 캐싱 : 이전에 조회한 도메인 이름과 해당하는 IP 주소를 저장하여 재요청시 사용 (도메인 설정할 때, TTL 설정값에 따라 이 캐싱 데이터 저장 시간이 결정됨)
- 데이터베이스 캐싱 : 데이터베이스 조회나 계산 결과를 저장(warm up)하여 재요청시 사용
- CDN : 원본 서버의 컨텐츠를 PoP 서버에 저장하여 사용자와 가까운 서버에서 요청 처리
- 어플리케이션 캐싱 : 어플리케이션에서 데이터나 계산 결과를 캐싱하여 반복적 작업을 최소화한다.
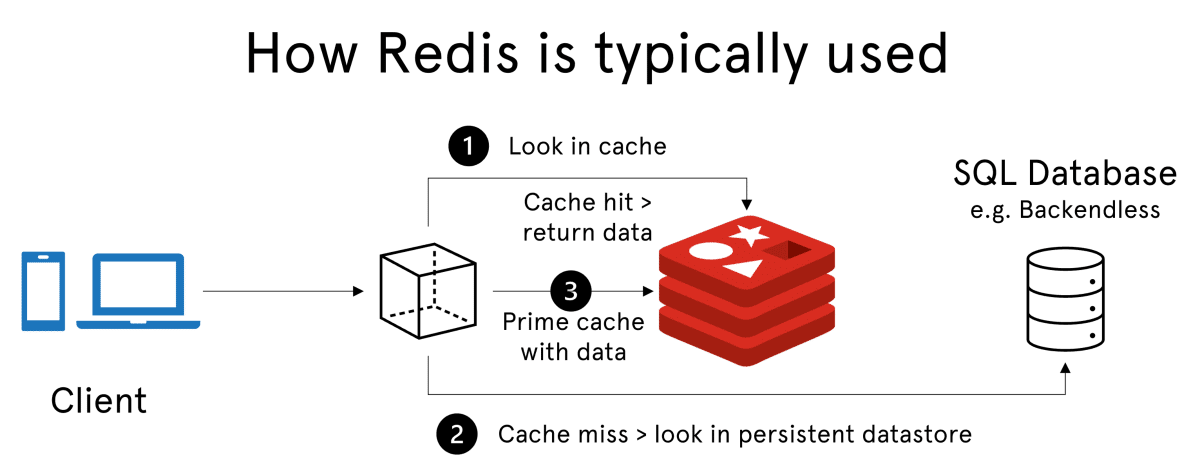
Cache Hit / Miss
✅ cache hit : 서버가 특정 데이터를 redis에 요청했을 때, redis가 관련 데이터를 가지고 있어 해당 요청에 대한 응답을 보내줄 수 있는 경우에는 cache hit되었다고 합니다.
❌ cache miss : 서버가 특정 데이터를 redis에 요청했을 때, redis가 관련 데이터를 가지고 있지 않거나 TTL이 만료되어 응답해줄 수 없는 경우에는 cache miss되었다고 합니다.
Cache-Aside Pattern
캐시를 사용하는 가장 기본적인 형태입니다.

클라이언트가 서버로 요청을 보냈을 때, 그 데이터를 redis에도 다루는 경우에는 서버가 redis로 요청을 보낼 것입니다.
이 때, redis에 그 데이터가 있으면(cache hit), redis에서 바로 데이터를 가져와 응답을 할 것이고, 만약 redis에 그 데이터가 없으면 DB에서 해당 데이터를 조회한 뒤에 cache를 업데이트 하고 나서 클라이언트에 응답하는 패턴을 말합니다.
이것 말고도 write throught, write behind와 같은 패턴도 있지만, 이는 일반적인 어플리케이션에서는 자주 사용되지 않습니다.