
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 싸피
- JUnit
- JPA
- 다익스트라
- BFS
- 코딩테스트실력진단
- 그래프
- 그리디
- 알고리즘
- SWEA
- 트러블슈팅
- DP
- 완전탐색
- 다시보기
- 코테
- 알고리즘기본개념
- Union Find
- Spring
- 코드트리
- 완탐
- SSAFY
- 유니온파인드
- 백준
- 자바
- 코딩테스트
- 기본유형
- Java
- database
- DFS
- 부분수열의합2
- Today
- Total
HwangHub
자바로 알고리즘 시작하기 2 - List, Queue 컬렉션 본문
자바로 자료구조 시작하기
자바는 자료의 관리를 용이하게 하는 많은 자료구조를 인터페이스와 구현 클래스를 정의하여 java.util 패키지에 모아두었고, 이를 컬렉션 프레임워크라고 부른다.
컬렉션 프레임워크의 구조
인터페이스를 통해 자바의 컬렉션 프레임워크가 어떤 구조를 갖고 있는지 이해해보자.
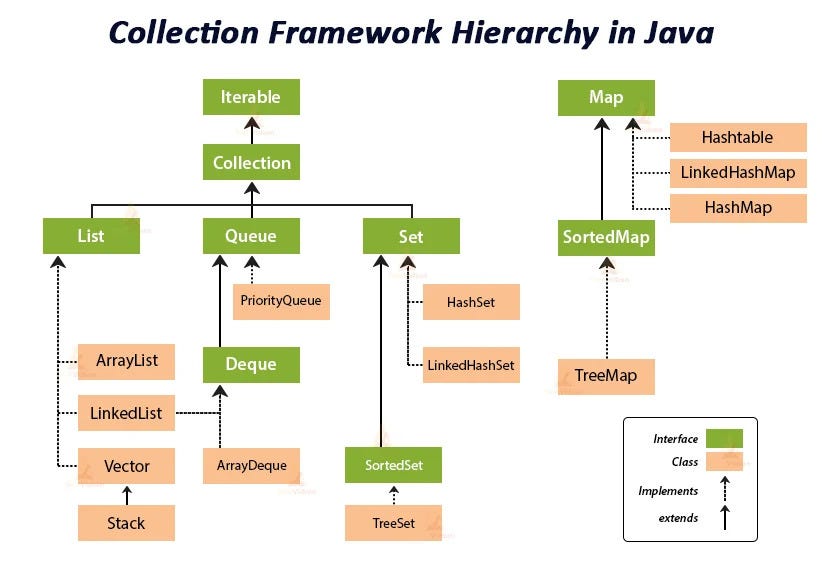
위 그림에서 초록색을 기준으로 보면 구조를 이해할 수 있다. 자바는 Iterable이라는 최상위 인터페이스를 기반으로 List, Set, Queue 컬렉션을 운영하고 있고, 번외로 Map이라는 게 존재한다.
컬렉션 인터페이스 둘러보기
자바를 잘 이해하고 있는 사람은 알겠지만, List, Set, Queue와 같은 인터페이스는 모두 Collection이라는 인터페이스를 상속하고 있기 때문에 기본적인 동작 메서드는 대부분 동일하게 지원한다. add(), get() 또는 contains(), isEmpty(), remove() 와 같은 메서드들이 지원되며, 이를 통해 자바를 사용하는 사람들이 각 컬렉션별로 번거로이 구별하여 학습하지 않아도 편하게 재사용이 가능하다. (인터페이스의 힘) 물론, 각 자료구조별로 add() 또는 remove()와 동일한 기능을 수행하더라도 자료구조에 따라 다른 이름의 메서드로도 지원된다. 그러면, 각 컬렉션 인터페이스를 가볍게 이해해보자.
List : 순서대로 element를 모아두는 컬렉션이다.(선형 자료구조) 구현체는 동적 배열인 ArrayList, 기본적으로 양방향 연결리스트인 LinkedList, 그리고 오늘날에는 사용하지 않는 동적 배열 Vector와 벡터를 이용하여 구현했던 Stack이 같이 있다.
*** (자바의 Vector와 Stack은 CPU 코어가 1개였을 시절에 만든 자료구조로, 상당히 연산 효율이 비효율적인 구현체이다. 오늘날에는 Concurrent- 류의 동시성 제어를 구현한 자료구조도 많이 제공하고 있고, Vector와 Stack 모두 ArrayList와 LinkedList로 대체가 가능하니 사용할 이유가 전혀 없다.)
Set : 기본적으로는 입력되는 element의 순서를 유지하지 않으며, 포함 여부를 판단할 때 주로 사용하는 컬렉션이다. 중복을 허용하지 않는다는 것이 가장 큰 특징이라, 실제로 알고리즘에 사용할 때에는 element의 중복을 제거할 때 많이 사용한다.
Queue : 선입선출 구조를 갖는 선형 자료구조이다. Queue 인터페이스는 내부적으로 Deque 인터페이스가 상속하고 있고, 이를 LinkedList 클래스에서 구현하고 있으므로 자바에서는 다형성을 이용하여 다음과 같은 방식으로 사용이 가능하다.
Queue<E> q = new LinkedList<>(); // 물론 ArrayDeque라는 구현체도 가능Map : Collection 인터페이스를 확장하지 않고 별도로 구현되어 있다. 그 이유는 Map은 다른 컬렉션들처럼
<element>끼리 모아두는 방식이 아니라,<key, value>형식으로 데이터를 모아두기 때문이다. 인터페이스가 다르므로 지원 메서드 이름도 조금씩 다르기도 하다.put(),containsKey()와 같은 방식으로 구성된다.*** Map 인터페이스에서도 HashTable이라는 클래스가 존재한다. 이것도 위에서 서술한 것 처럼 자바 초창기에 CPU 1코어를 기준으로 구현된 클래스라서 사용을 지양해야 한다. 이런 것들이 오늘날에는 사용하기에 적합하지 않음에도 남아있는 이유는 자바가 하위호환성을 철칙처럼 지키고 있는 언어이기 때문이다. 전 세계적으로 자바를 이용하여 많은 서비스가 구성되어 있는데, 엔터프라이즈 서비스들은 코드가 쉽게 변하기 어렵기 때문에 어느 곳에서는 이런 코드를 사용하고 있을 것을 고려하여 jdk 버전이 업그레이드 되더라도 하위호환성을 꼭 지켜주고 있을 뿐이다. (=즉, 오늘날 새로 코드를 작성하는 입장에서는 HashTable와 같은 걸 쓸 이유가 전혀 없다.)
List : 선형 자료구조
자료구조는 크게 다음과 같이 분류된다.
- 메모리 공간 기반의 "연속" 방식
- 포인터 기반의 "연결" 방식
List를 이해하기 전에, 태초에 선형 자료구조로 사용하던 정적 배열에 대하여 먼저 알아보자.
(정적) 배열(Static Array)
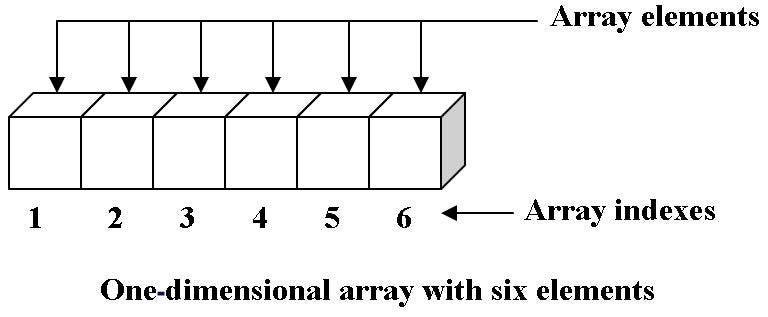
배열은 연속 방식의 가장 기본이 되는 자료형이다. 값의 집합으로 구성되면서 하나 이상의 인덱스 또는 키로 식별된다.
배열은 크기를 지정하고 해당 크기만큼 연속된 메모리 공간을 할당받는 작업을 수행하는 자료형이다. 자바 코드로 보면 다음과 같다.
int[] arr = new int[10];
for (int i = 0; i < 10; i++) {
arr[i] = i;
}한번 생성된 배열은 그 크기를 변경하는 것이 불가능하다. 배열을 처음 선언할 때, 실제 메모리에 해당 크기만큼만 연속되게 공간을 할당해두기 때문이다. 가령 위의 예시처럼 자바 int타입은 한 개당 4byte이므로, arr이라는 배열에게 할당된 메모리 공간은 연속된 40byte만큼의 공간인 것이다. (메모리 접근 또한 1byte가 기준이다.)
조회
이렇게 연속된 메모리 주소를 할당받았기 때문에 배열 상 어느 위치에 있던 바로 해당 주소에 접근하면 되므로 O(1)에 조회가 가능하다.
삽입/삭제
삽입 시에 맨 끝에 삽입하는 경우에는 O(1)이겠지만, 일반적으로 중간에 삽입하는 경우에는 그 삽입 인덱스로부터 뒤의 모든 숫자를 한 칸씩 뒤로 옮겨야 하므로 O(n)의 시간복잡도를 보인다. 최악의 경우는 맨 앞에 삽입하는 경우이다.
삭제의 경우에도 삽입과 마찬가지로, 맨 뒤의 엘리먼트 삭제는 O(1)이지만, 중간 또는 맨 앞 엘리먼트의 삭제는 O(n)의 시간이 걸린다.
동적 배열(Dynamic Array)
고정된 크기만큼 연속된 메모리를 할당하는 것이 배열의 핵심적인 특징이다. 하지만 실제 데이터를 처리하다보면 전체 크기를 고정해두기 까다로운 경우가 많다. 너무 적은 영역을 할당해두면 모자라기 쉽고, 너무 많은 영역을 할당해두면 메모리가 낭비될 것이다. 이러한 고민을 바탕으로 등장한 것이 '동적 배열'이다.
자바에서는 ArrayList가, C++에서는 std::vector가 있다. 파이썬에서는 애초에 정적 배열은 존재하지 않고, 모든 배열이 동적 배열로 생성된다.
원리
동적 배열의 원리는 언어마다 구현된 상세 로직이 상이하겠지만, 기본적인 틀은 아래와 같다.
- 먼저 배열 크기의 초깃값을 작게 잡아 배열을 생성한다.
- 데이터가 추가되면서 배열이 가득 차게 되면, 크기를 늘린 배열을 새로 생성하고 이전 엘리먼트를 전부 복사해준 뒤 기존 배열을 지우는 방식이다.
대개의 경우 Doubling이라 하여 2배씩 크기를 늘려주는 방식을 취한다. 자바의 ArrayList는 어떻게 되어있는지 살펴보자.
public class ArrayList<E> extends AbstractList<E> implements List<E>, ... {
// ...
private static final int DEFAULT_CAPACITY = 10;
// ...
int newCapacity = oldCapacity + (oldCapacity >> 1);
// ...
}자바에서는 위와 같이 기본 크기가 10으로 설정되어 배열을 설정한다. 이후 공간이 가득 차면 비트 연산자를 활용하여 크기를 늘려주도록 grow() 메서드가 정의되어 있다. 이렇게 자바는 1.5배씩 더 큰 메모리 영역을 할당하면서 동적 배열을 구현하였다.
조회
동적 배열도 내부적으로는 배열이기 때문에 메모리의 연속성을 이용한 자료구조이므로, 조회시 성능이 O(1)이다.
더블링
일반적인 삽입/삭제 상황에서도 위 배열과 동일한 시간복잡도를 가질 것이다. 하지만 삽입 시 만약 동적 배열의 용량이 가득 차면 크기를 늘려야 한다. 이 때에는 새로운 메모리 공간에 1.5배의 배열을 할당하고 기존 n개의 데이터를 복사하는 작업이 필요하므로 O(n)만큼의 시간이 걸리게 된다.
연결 리스트(LinkedList)

연결 리스트는 컴퓨터과학에서 배열과 함께 가장 기본이 되는 선형 자료구조 중 하나이다. 연결 리스트는 배열과 달리 물리적으로 연속된 메모리 공간에 데이터를 저장하지 않고, 데이터 엘리먼트가 데이터와 포인터로 구성된 노드에 저장된다.
이를 이용하여 다양한 자료형을 구현한다. 연결리스트는 이론적으로 각 노드가 다음 노드만 가리키는 single-linked list 형식과 이전 노드와 다음 노드를 모두 가리키는 double-linked list 형식이 존재한다.자바에서는 기본적으로 double-linked list로 구현되어 있으며, 이를 활용하여 Queue 뿐만 아니라 양방향 큐인 Deque도 구현될 수 있다.
다음은 자바의 연결리스트 구현 코드 일부이다.
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, ... {
transient int size = 0;
/**
* Pointer to first node.
* */
transient Node<E> first;
/**
* Pointer to last node.
* */
transient Node<E> last;
// ...
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
// ...
}
}조회
연결 리스트는 배열과 달리 데이터의 위치를 바로 알 수 없기 때문에 특정 인덱스에 접근하기 위해서는 전체를 순서대로(선형으로) 탐색해야 한다. 따라서 O(n)의 시간이 소요된다.
삽입/삭제
하지만 특정 데이터를 단순히 삽입/삭제하는 작업은 근처 포인터를 이용하여 바로 작업할 수 있으므로 O(1)의 시간이 소요된다. 물론, 중간에 삽입/삭제하기 위해서는 해당 노드를 탐색하는 시간이 O(n)만큼 필요하다.
큐(Queue) : 특징을 갖는 선형 자료구조
그러면 이제부터는, element를 순서대로 단순 저장하는 방식이 아니라, 순서를 의미있게 사용하는 선형 자료구조를 이해해보자.
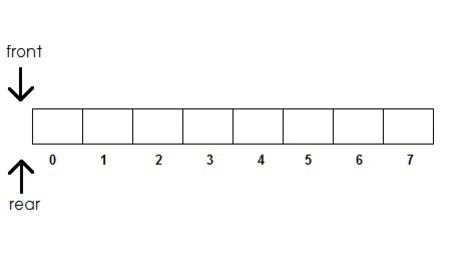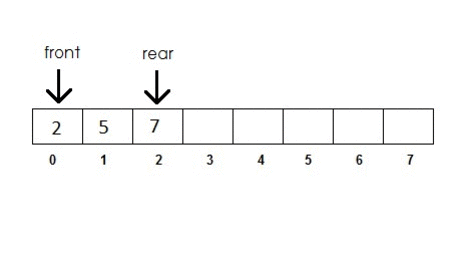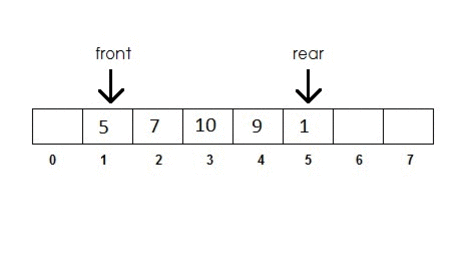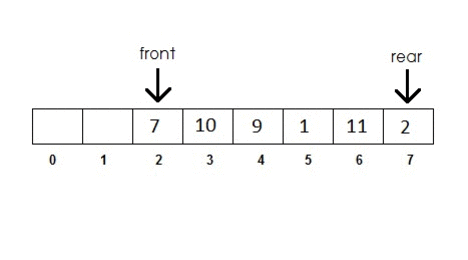
큐는 선입선출(FIFO; First In First Out) 방식으로 처리되는 자료구조이다. 이는 기본적인 Queue 뿐만 아니라 양방향 큐인 Deque 그리고 Priority Queue까지 다양한 variation이 있으며, 모두 자주 사용되는 데이터 타입이다.
조회
큐에서 필요한 조회는 "맨 앞의 요소가 무엇인지"이다. 지금껏 다뤘던 배열이나 연결리스트는 여러 데이터를 효과적으로 관리할 수 있는 방법이었다면, 큐 또는 이후에 다룰 스택의 경우에는 FIFO, LIFO 구조를 이용하여 당장 필요한 값만 순서대로 알면 되기 때문이다.
일반적으로 Queue에서는 맨 앞의 요소를 property로 관리하기 때문에 조회에 필요한 시간복잡도는 O(1)이다.
삽입/삭제
큐에서의 삽입/제거는 자바에서는 offer(), poll()이라고 표현하며, 큐의 뒷부분에 새로운 요소를 추가하거나 제거하는 연산이다. 큐의 맨 뒷 요소 또한 property로 관리되므로 이 연산의 시간복잡도 또한 O(1)이다.
그 외 연산
- size : 큐의 크기를 확인하는 연산인데, 이 또한 자바에서는 기본적으로 Collection 프레임워크에서 지원하고 있는 관리 요소라서 시간복잡도가 O(1)이다.
- isEmpty : 위와 마찬가지이다.
구현
자바에서는 Queue 인터페이스에서 offer(), poll(), peek()과 같은 메서드를 정의하고 있고, 이를 LinkedList에서 구현하고 있다. ArrayDeque에서도 구현되어 있다. 그렇다면, 뭘 사용해야 할까?
LinkedList는 연결 리스트로 구현되어 있어서 중간 삽입/삭제에 유리한 성능을 보이지만, Queue의 구조를 이해해보면 끝에 추가하고 앞에서 빼내고 하는 방식이 주를 이루기 때문에 내부적으로 배열 방식으로 구현되어 있는 ArrayDeque 클래스를 이용하여 사용하는 것을 추천한다. (특징을 고려할 때, Queue를 사용하기에 성능상 더욱 이점이 있는 구현체가 ArrayDeque인 것임)
import java.util.LinkedList;
import java.util.Queue;
public class QueueExample {
public static void main(String[] args) {
// 큐 생성
Queue<String> queue = new ArrayDeque<>();
// 큐에 요소 추가
queue.add("element1"); // offer()와 동일
queue.add("element2");
queue.add("element3");
System.out.println("Initial Queue: " + queue);
// 큐에서 요소 제거
String removedElement = queue.poll();
System.out.println("Removed Element: " + removedElement);
System.out.println("Queue after removal: " + queue);
// 큐의 첫번째 요소 확인
String peekElement = queue.peek();
System.out.println("Peek Element: " + peekElement);
System.out.println("Queue after peek: " + queue);
}
}
활용
큐가 가장 대표적으로 사용되는 알고리즘은 ==BFS==이다. 그 외에도 프린터 대기열, 프로세스 스케줄링, 네트워크 패킷 트래픽 관리 등에 사용된다. 또한 캐시 알고리즘 중 LRU(Least-Recently Used) 알고리즘에서도 큐를 이용하여 캐시 데이터를 관리하며, LFU(Least-Frequently Used) 알고리즘 또한 우선순위 큐를 이용하여 구현할 수 있다.
덱(Deque)
Deque(Double Ended Queue)는 이름에서 알 수 있듯이 양쪽 끝에서 삽입과 삭제가 모두 가능한 자료구조이다. 이로 인해 Stack과 Queue의 특성을 모두 가지고 있다. 따라서 위에서 Stack의 구현체로 ArrayDeque를 사용하는 걸 볼 수 있었다.
조회
- peekFirst(): Deque의 앞쪽 요소를 조회하는 연산으로, 시간 복잡도는 O(1)이다.
- peekLast(): Deque의 뒷쪽 요소를 조회하는 연산으로, 시간 복잡도는 O(1)이다.
삽입/삭제
- addFirst(element): Deque의 앞쪽에 요소를 삽입하며, 시간 복잡도는 O(1)이다.
- addLast(element): Deque의 뒷쪽에 요소를 삽입하며, 시간 복잡도는 O(1)이다.
- removeFirst(): Deque의 앞쪽 요소를 제거하고 return한다. 시간 복잡도는 O(1)이다.
- removeLast(): Deque의 뒷쪽 요소를 제거하고 return한다. 시간 복잡도는 O(1)이다.
구현
자바에서는 덱을 연결리스트로 구현해 두었다. Queue의 구현체가 연결리스트인데, Deque는 Queue를 상속하고 있는 구조라서 이는 자명하다고 할 수 있다. 물론 ArrayDeque를 사용해도 된다. 일단 예시에서는 LinkedList로 하겠다.
Deque<String> deque = new LinkedList<>();
// 요소를 앞쪽에 추가
deque.addFirst("element1");
deque.addFirst("element2");
// 요소를 뒷쪽에 추가
deque.addLast("element3");
deque.addLast("element4");
System.out.println("Initial Deque: " + deque); // Initial Deque: [element2, element1, element3, element4]
// 앞쪽 요소 제거
String removedFirst = deque.removeFirst();
System.out.println("Removed from front: " + removedFirst); // Removed from front: element2
// 뒷쪽 요소 제거
String removedLast = deque.removeLast();
System.out.println("Removed from back: " + removedLast); // Removed from back: element4
System.out.println("Final Deque: " + deque); // [element1, element3]활용
팰린드롬이나 슬라이딩 윈도우처럼 양옆으로 늘줄늘줄하는 알고리즘에 사용될 수 있다.
우선순위 큐(Priority Queue)
우선순위 큐는 각 요소가 우선순위를 가진 자료구조이다. 요소들은 우선순위에 따라 정렬되며, 가장 높은 우선순위를 가진 요소가 가장 먼저 꺼내진다. 자바에서는 이를 최소 힙(min heap)으로 구현한다. 내부적으로는 트리의 종류인 힙으로 구성되어 있지만 인터페이스가 큐인 이유는, 규칙에 따라 나올 순서가 된 녀석이 차례대로 나오기 때문이다.
조회
- peek(): 우선순위가 가장 높은 요소를 조회한다. 시간 복잡도는 O(1)이다.
삽입/삭제
- offer(element): 우선순위 큐에 요소를 삽입한다. 시간 복잡도는 O(log n)이다.
- poll(): 우선순위가 가장 높은 요소를 제거하고 반환한다. 시간 복잡도는 O(log n)이다.
우선순위 큐에서 삽입/삭제의 시간복잡도가 O(log n)인 이유는 우선순위 큐가 힙으로 구현되어있기 때문이다. 값이 추가되고 지워진 이후에는 내부 구조가 힙으로 유지되어야 하기 때문에 추가/삭제 후 힙 정렬을 수행해야 한다. 힙은 완전 이진 트리이므로 그 높이가 log n을 넘지 않으니 연산의 시간복잡도는 O(log n)이다.
구현
구현은 Queue 인터페이스에 PriorityQueue라는 구현체를 활용하여 사용이 가능하다. 이 구현체를 들여다보면 heap으로 구현되어 있다고 javadoc에 나와 있으며, 신기하게도 내부 element 관리는 동적 배열을 이용하여 구현되어 있다.
Queue<Integer> priorityQueue = new PriorityQueue<>();
// 요소를 큐에 추가
priorityQueue.offer(4);
priorityQueue.offer(2);
priorityQueue.offer(1);
priorityQueue.offer(3);
System.out.println("Initial PriorityQueue: " + priorityQueue); // Initial PriorityQueue: [1, 3, 2, 4]
// 가장 우선순위가 높은 요소 제거
Integer removedElement = priorityQueue.poll();
System.out.println("Removed Element: " + removedElement); // Removed Element: 1
System.out.println("PriorityQueue after removal: " + priorityQueue); // PriorityQueue after removal: [2, 3, 4]전능하신 chat GPT에게 우선순위 큐가 배열로 구현되어 있는 이유를 물어봤다.
->
자바에서 우선순위 큐(PriorityQueue)는 일반적으로 이진 힙(Binary Heap)을 기반으로 구현되어 있습니다. 이진 힙은 완전 이진 트리(Complete Binary Tree)의 일종으로서, 힙 속성을 만족하는 트리를 의미합니다. 힙 속성이란 모든 노드가 자식 노드보다 크거나(또는 작거나) 함을 의미합니다.
이진 힙은 배열을 사용하여 효율적으로 구현할 수 있습니다. 배열의 인덱스를 이용하여 특정 노드의 부모 노드와 자식 노드를 쉽게 찾을 수 있기 때문입니다. 따라서, 자바의 PriorityQueue는 내부적으로 배열을 사용하여 이진 힙을 구현하고 있습니다.
활용
다익스트라 알고리즘이 가장 대표적으로 우선순위 큐를 사용하는 알고리즘이다.
스택(Stack)
Queue처럼 나름의 규칙에 따라 element가 들어가고 나오는 Stack에 대하여 알아보자.
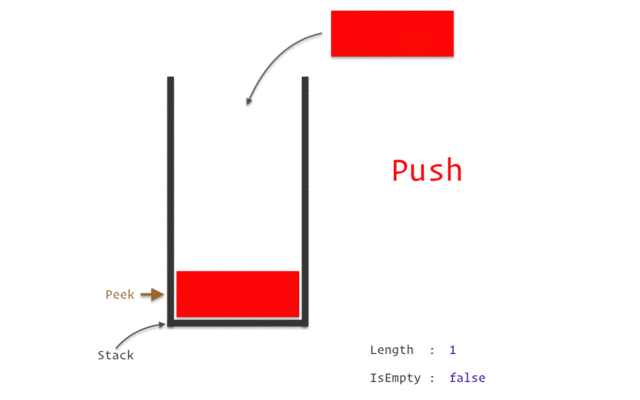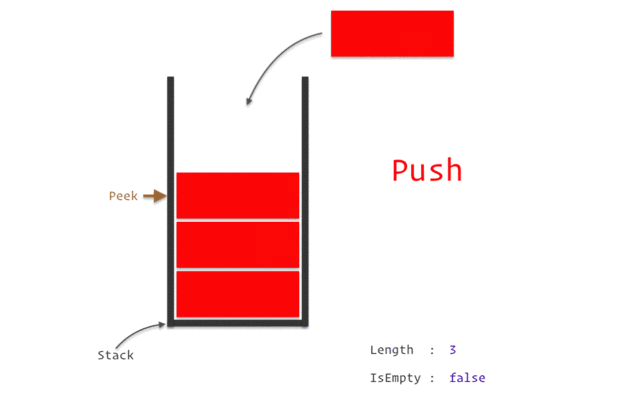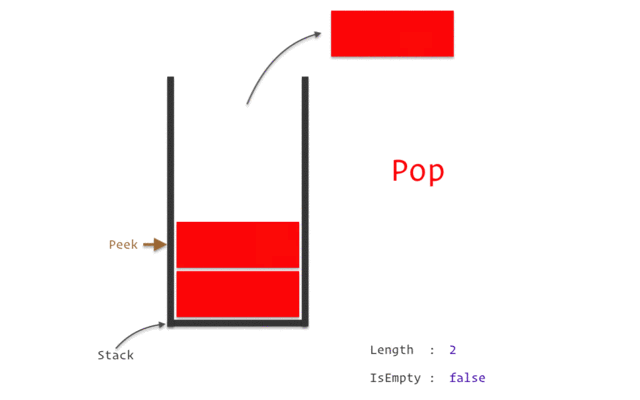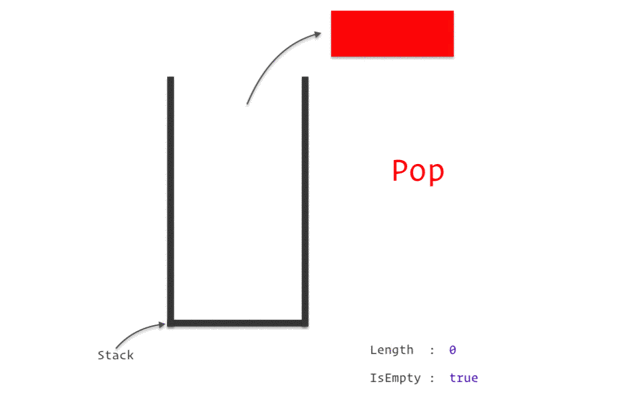
스택은 후입선출(LIFO; Last In First Out) 구조로 데이터를 처리하는 자료형이다. 이는 큐와 같이 가장 오래된 자료구조 중 하나로, 운영체제 시스템 구현에도 많이 사용된 자료구조이다.
조회
peek()
맨 위의 노드를 제거하지 않고 조회하는 연산이다. 당연하게도, O(1)만큼의 시간이 소요된다.
삽입/삭제
stack에서는 push() / pop()연산이라고 일컬으며, 맨 위 노드에 새로운 노드를 추가하거나 기존 top 노드를 제거하는 연산이다. 이 또한 top 노드를 관리하고 있기 때문에 O(1) 만큼의 시간이 소요된다.
그 외 연산
- isEmpty (비어 있는지 확인): 스택이 비어있는지 계산하는 연산이다. 이 또한 O(1) 만큼의 시간이 소요된다.
구현
자바에서는 연결 리스트로 스택을 구현하기도 하고, 연결 리스트를 바탕으로 구현되어 있는 Deque을 바탕으로 구현하기도 한다. 우선은 간단하게 연결 리스트로 구현해보면 아래 코드로 나타낼 수 있다.
class Node {
int data;
Node next; // single linked list
public Node(int data, Node next) {
this.data = data;
this.next = next;
}
}
class Stack {
Node top;
public Stack() {
this.top = null;
}
public void push(int data) {
// 입력된 데이터로 신규 노드를 생성하고, 기존의 마지막 노드는 다음 노드가 된다.
this.top = new Node(data, this.top);
}
public int pop() {
// top 노드의 값을 추출한다.
int data = this.top.data;
// top 노드를 갱신한다. (기존 top 제거)
this.top = this.top.next;
return data;
}
}또한 자바에서 지원하는 Deque를 이용한 Stack 구현법은 아래와 같다. 이는 자바 공식 문서에서도 권고하고 있는 내용이다.
import java.util.ArrayDeque;
import java.util.Deque;
public class StackExample {
public static void main(String[] args) {
// ArrayDeque를 사용하여 스택 생성 (Deque의 구현체)
Deque<Integer> stack = new ArrayDeque<>();
// 스택에 요소 추가 (push)
stack.push(1);
stack.push(2);
stack.push(3);
// 스택에서 요소 제거 및 반환 (pop)
int poppedElement = stack.pop();
System.out.println("Popped Element: " + poppedElement);
// 스택의 맨 위 요소 확인 (peek)
int topElement = stack.peek();
System.out.println("Top Element: " + topElement);
// 스택이 비어 있는지 확인
boolean isEmpty = stack.isEmpty();
System.out.println("Is Stack Empty: " + isEmpty);
}
}주의할 점은, 자바 초창기에 Vector를 활용하여 구현된 Stack 구현체는 사용하는 것은 매우 지양되어야 한다는 것이다. 이는 과거 CPU 코어가 1개일 때를 기준으로 생성된 구현체이기에, 모든 연산에서 코어를 단 한개만 사용하고 다른 쓰레드에서는 처리할 수 없도록 lock을 걸어버린다. 즉, 64코어 CPU일지라도 64번을 동시에 읽지 못하고 차례대로 줄서서 작업을 처리해야 한다는 이야기다. 이는 실무에서 절대 사용하지 않는 자료구조라는 의미이며, 이를 쓰지 않고도 충분히 구현할 수 있는데, 구태여 이제는 자바 공식 문서에서도 사용을 지양하길 권고하는 클래스를 사용할 필요가 없다. 동시성 제어를 위해서는 성능이 더욱 개선되어있는 ConcurrentLinkedDeque 또는 ConcurrentHashMap 등의 타입이 존재한다.
활용
스택은 프로그래밍이라는 개념이 등장했을 때부터 사용된 가장 고전적인 자료구조 중 하나로, '함수 호출 및 복귀', '재귀 호출', '지역변수, 매개변수 저장' 등에 대표적으로 사용된다. "나중에 들어간 게 먼저 나온다"라는 원리를 이용하여 대표적으로 스택을 사용하는 알고리즘은 DFS, 백트래킹이 있다. 두 개 모두 스택으로 관리가 가능하지만, 컴퓨터 내부적으로 재귀를 스택으로 관리하므로 우리는 사실 재귀 함수를 로직에 사용함으로써 대체하고 있다.
'CS-STUDY > 자료구조 & 알고리즘' 카테고리의 다른 글
| 자바로 알고리즘 시작하기 4 - 사용자 정의 객체 정렬 (0) | 2024.01.23 |
|---|---|
| 자바로 알고리즘 시작하기 3 - Set, Map 컬렉션 (1) | 2024.01.23 |
| 자바로 알고리즘 시작하기 1 - 알고리즘 왜 하나요? (0) | 2024.01.07 |
| BST의 시간복잡도 O(log N) 증명하기 (1) | 2024.01.07 |
| [가벼운 고민] linked list에서 순서에 관계없이 노드를 추가할라면 어디에 추가하는게 가장 효율적인가? (0) | 2023.11.07 |