
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- DFS
- SSAFY
- 백준
- Spring
- JPA
- 기본유형
- Union Find
- 다시보기
- 부분수열의합2
- 코드트리
- 코테
- SWEA
- 다익스트라
- 완전탐색
- 싸피
- 완탐
- DP
- 알고리즘
- Java
- 그래프
- 자바
- database
- 유니온파인드
- 그리디
- JUnit
- 코딩테스트실력진단
- 코딩테스트
- 트러블슈팅
- 알고리즘기본개념
- BFS
- Today
- Total
HwangHub
MySQL로 이해하는 데이터베이스 1 - 이해와 설계 본문
메인 출처 : (도서) MySQL로 배우는 데이터베이스 개론과 실습
참고 링크 : medium.com
데이터베이스는 많은 종류가 있지만, 우리는 MySQL을 기준으로 관계형 데이터베이스를 학습하고 있으므로 앞으로 서술되는 많은 내용은 관계형 데이터베이스에 대한 내용입니다.
데이터베이스란
데이터베이스는 조직에서 필요한 정보를 관리하기 위해 논리적으로 연관된 데이터를 구조적으로 통합해 둔 것입니다. 즉, 데이터베이스는 구조화된 데이터 덩어리를 의미하며, MySQL이나 Oracle DB와 같은 것들은 데이터베이스를 관리하는 데이터베이스 "관리 시스템"입니다. Database Management System(DBMS)는 데이터 관리를 아날로그식으로 장부에 적어서 관리하던 시대를 지나, 디지털화되면서 데이터를 잘 관리할 수 있는 시스템의 필요에 따라 탄생하였습니다.
데이터베이스 시스템은 데이터의 검색과 변경 작업 등을 주로 수행하기 위해 디자인되어 있습니다. 우리가 흔히 말하는 Create, Read, Update, Delete와 같은 작업을 말이죠.
데이터베이스(관리하고자 하는 데이터 덩어리)를 디지털 환경에서 관리하기 위해서는 데이터베이스 시스템을 구축해야 합니다. 데이터베이스 시스템은 다음 3가지 요소로 구성됩니다.
- 데이터베이스 관리 프로그램 DataBase Management System(DBMS; MySQL workbench 등)
- 데이터베이스
- 데이터 모델 (schema)
데이터 모델
모든 것을 이해하기에 앞서, 데이터가 어떻게 입력되는지 이해하기 위해서는 데이터 모델을 이해해야 합니다.
관계형 데이터베이스는 많은 데이터를 효과적으로 관리하기 위해 입력되는 데이터의 양식을 정의합니다.

우리가 c언어에서 구조체를 정의하거나, 자바에서 객체를 선언하듯이, 관리하고자 하는 데이터들은 연관성으로 연결하면 하나의 모델로 묶을 수 있습니다. 가령 "고객의 이름", "고객의 이메일"과 같은 정보는 "고객"의 정보의 속성값이라고 이해해볼 수 있는 거죠. 관계형 데이터베이스에서는 이런 연관성을 갖는 데이터들을 그룹화하여 관리합니다. 이런 각 그룹들은 Relation이라고 칭하는데, 이게 실제 데이터베이스 상에서는 마치 도표처럼 보여서 Table이라고 더 많이 부릅니다. 이렇게 여러 테이블이 하나의 관계형 데이터베이스에 생성될텐데, 각각 하나의 테이블을 정의하는 걸 모델링이라고 합니다.
그럼 이런 테이블에 데이터가 들어가는 모양은 어떨까요?
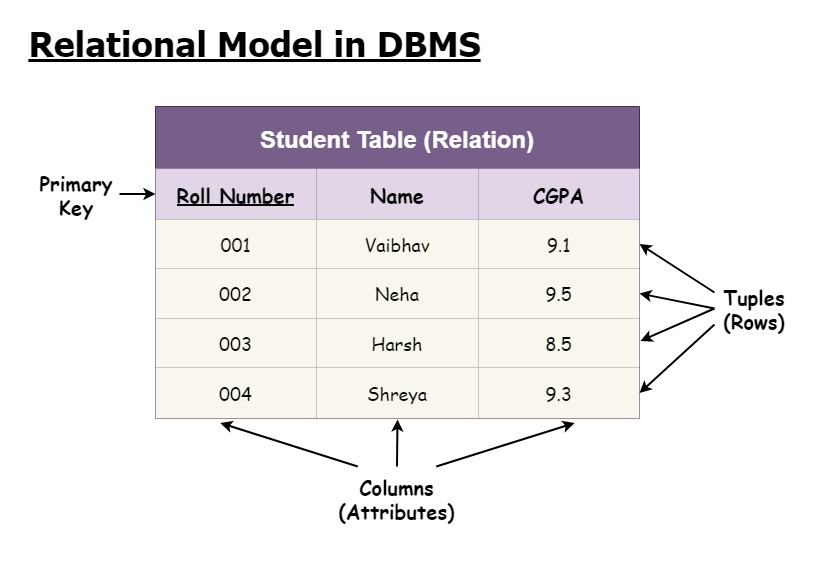
위 그림을 보면 왜 Table이라고 부르는지 바로 이해가 되실 겁니다. 마치 수학에서 많이 보던 '표'처럼 생겼죠? 이렇게 테이블에 정의된 속성값 양식에 따라 데이터가 각각 저장되고, 각각의 데이터는 tuple 또는 row 또는 record라고 부릅니다. 뭐로 불러도 상관 없을 정도로 혼용하는 것 같습니다. 그리고 각 속성은 attribute라고 하기도 하고 column이라고도 합니다. 그리고 각 튜플을 명확히 구분하기 위한 식별자인 Primary key라는 것도 있습니다. 이는 아래 KEY 파트에서 좀 더 다루겠습니다.
키 (KEY) : 데이터베이스 레코드 식별자
관계 데이터베이스에서 key는 테이블의 많은 튜플들 중 특정 튜플을 식별할 때 사용하는 속성입니다. 관계 데이터베이스에서는 중복되는 데이터라는게 존재할 수 없기 때문에 구분자가 반드시 하나는 필요하거든요.
이 키는 각 튜플을 구분하는 역할도 하고, 릴레이션 간 관계를 맺을 때에도 사용합니다. 한번 이에 대하여 정리해 보겠습니다.
슈퍼키
슈퍼키(Super key)는 튜플을 유일하게 식별할 수 있는 하나의 속성 혹은 속성의 집합입니다. 튜플을 유일하게 식별할 수 있는 값이면 모두 슈퍼키가 될 수 있습니다. 다음 예시와 함께 이해해 보겠습니다.
각 속성에 대한 설명은 다음과 같습니다.
- id : 모든 튜플이 고유하게 갖는 임의의 유니크 숫자 값이다.
- name : 이름을 담고 있으므로, 동명 이인에 대하여는 중복되는 데이터이다.
- email : 이메일은 회원의 중복 가입 여부를 판단하는 값으로 사용되는 유니크 값이다.
그럼 슈퍼키는 어떻게 될까요? 나열하면 다음과 같습니다.
(id), (email), (id,name), (id,email), (email, name), (id,name,email)
즉, 반드시 구분될 수 있는 값이 있는 거라면 그 값을 포함하는 부분집합도 슈퍼키가 될 수 있다는 겁니다. 하지만 보시다시피 슈퍼키 구성에는 name과 같이 단독으로는 튜플을 식별할 수 없는 속성도 포함되는 것을 허용하므로 슈퍼키 구성 속성이 많아지는 걸 열어두게 되고, 만약 이렇게 많은 속성을 한번에 묶어서 키로 관리하게 되면 관계 표현이 복잡하고 사용성이 떨어집니다.
따라서 이는 개념적인 영역에만 머물게 되고, 실질적으로는 튜플을 식별할 수 있는 최소한의 속성 집합을 사용하게 되는 게 일반적입니다.
후보키
후보키(Candidate key)는 모든 속성이 단독으로 튜플을 식별할 수 있어야 하는 속성의 집합입니다. 단독으로도 구분되니, 그 속성들의 집합으로는 더 당연히 각 튜플이 구분되겠죠. 즉 슈퍼키 중 (id, name)과 같은 경우는 후보키가 될 수 없습니다.
이는 슈퍼키는 복잡성이 높아 보통 실제로 활용되지 않는 개념이고, 데이터베이스에 대한 이야기를 할 때 기본적으로 key라고 칭하면 이 후보키를 의미하는 것이 일반적입니다.
그럼 다시 이미지를 참고해서 후보키를 뽑아볼까요?
후보키는 다음과 같습니다.
(id), (email), (id,email)
위에서 언급은 안 했었는데, (id, email)처럼 두 개 이상의 속성으로 이루어진 키를 복합키(composite key)라고 합니다. 이에 대하여는 FK에서 다시 다루겠습니다.
기본키
기본키(Primary key)란 여러 후보키 중 선정된 하나의 대표 키를 의미합니다. 위에서 테이블에 대하여 설명할 때 있던 Primary key가 바로 기본키입니다.
후보키 중 하나를 선정하여 "각 튜플을 이 속성값으로 구분하겠다" 지정하는 겁니다. 모든 테이블은 반드시 하나의 PK를 설정해줘야 하며, 이는 null이 될 수 없는 값이여야 합니다. 그래서 보통은 1,2,3,4,...와 같은 패턴으로 자동으로 각 튜플을 넘버링하는 값을 PK로 종종 설정합니다. 이에 대하여는 아래에서 다시 설명하겠습니다.
다음은 무결성 조건 외에 기본키를 설정할 때 고려해야 하는 특징입니다. 이는 엄격한 기준은 아니지만, 준수하는 것을 권장하는 개념입니다.
- Uniqueness : 다른 Row로부터 식별이 가능하도록 유일한 값일 것
- Stability : 수정이 일어나지 않을 것
- Irreducibility : (비환원성) 복합키를 사용한다면 그 키의 어느 칼럼이건 수정하는 순간 PK의 유일성이 깨질 수 있으니 주의할 것
- Simplicity : (sequence number와 같이) 가급적 읽기 쉽고, 기억되기 쉬운 값을 적용할 것
pk auto increment 전략은 위 특징을 충족하는 간편한 방법이지만, 만약 저처럼 "항상 auto increment를 하는 게 능사는 아닐 것 같은데?"와 같은 의문을 품고 사는 사람이라면 이 링크가 도움이 될 수 있을 것 같습니다.
위 예시를 다시 보면, roll number라는 속성이 PK로 설정되어 있는데, 이게 1,2,3,4... 로 증가 수열을 이루며 모든 튜플에 대하여 식별자 역할을 해주고 있는 걸 확인할 수 있습니다. 1부터 시작하고 계속 1씩 증가시켜주니 절대 중복되지도, null이 되지도 않으니 PK로 선정되기에 딱인 것으로 보이네요.
추가로, PK 설정시 자연키(natural key)와 인공키(artificial key)라는 개념도 존재합니다.
자연키는 일반적으로 "주민등록번호"처럼 세상에 의미를 갖고 자연스럽게 존재하는 유니크한 key 데이터를 의미합니다. 과거에는 이를 PK로 설정하기도 했다고 하고, 이러한 자연키들을 복합키로 묶어서 종종 PK로 설정했다고 합니다.
하지만 오늘날에는 위의 roll number와 같이 시스템에서 별다른 의미 없이 자동으로 생성하는 식별자 역할만을 위한 인공 키(aritificial key)를 별도 속성으로 추가하여 PK로 사용하는 일이 많아졌습니다. 이는 여러 목적이 있는데요.
- PK와 같은 ID 데이터가 클라이언트에 노출될 수 있는 상황도 많은데 "주민등록번호"와 같은 의미가 있는 데이터를 외부에 노출시키는 것이 보안상 문제가 발생하기도 하며,
- 가령 어떤 테이블은 유니크한 데이터가 전혀 없어서 PK 선정이 까다롭기 때문입니다.
따라서 요즘은 인공키를 이용하여 PK를 설정하는 것이 일반적이고, 이는 다른 데이터 대신 PK 역할을 수행하는 key라 하여 대리키(surrogate key)라고도 부릅니다.
대체키
대체키(alternate key)는 기본키로 선정되지 못한 후보키를 일컫습니다. 위 예시에서 Users 테이블의 id를 PK로 설정했다면 email이 대체키가 되겠네요. 이건 중요 개념이 아니라서 이쯤 하겠습니다.
외래키
외래키(foreign key)는 다른 테이블의 기본키를 참조하는 속성을 의미합니다. 서비스를 구성하다 보면 유저 정보 외에도 많은 정보가 있을 겁니다. 우리가 자주 사용하는 인스타그램만 하더라도 "포스트"라는 테이블이 있다고 하면, 이미지들과 좋아요 개수, 댓글 개수와 같은 정보들이 있을 수 있겠죠.
근데 내 게시글에 좋아요를 누른 유저들의 정보는 어떻게 저장해야 할까요? 게시글 테이블의 한 속성에 여러 유저 테이블 row를 저장하는 리스트를 둘 수 있을까요? 여기서 왜 관계형 데이터베이스가 "관계형" 데이터베이스인지 밝혀집니다. 관계형 데이터베이스에서는 이를 테이블 간 "관계 설정"으로 풀어냈습니다.

위 사진에서 보면 Members, Member Signups, Class Schedule, Classes, Instructors, Types 와 같은 테이블이 있습니다. 그리고 각각 id라는 PK를 갖고 있습니다. 이제 또 보이는 것이 foreign key(FK)인데요. 잘 보시면 각 FK는 다른 테이블의 PK와 연결되어 있는 것을 확인할 수 있습니다. 그럼 예시에 있는 가장 간단한 예시인 class schedule과 instructor 테이블 간의 관계를 통해 FK로 구현하는 현상을 설명해 보겠습니다.
- classe schedule은 어떤 클래스가 몇시에 시작하고 몇시에 끝나는지 나타낸다.
- instructors는 각 클래스에 참여하는 강사의 이름을 나타낸다.
- 한 강사가 여러 수업에 참여하는 경우, 강사 테이블에 참여 수업 리스트를 속성으로 지정하지 않고, class schedule에서 강사의 PK값을 저장하여 참여 강사 정보를 저장한다.
이처럼 속성에 리스트를 두는 방식 보다는 각 데이터 간의 관계성을 담을 수 있도록 FK라는 속성값을 두게 하여 효과적으로 데이터를 관리할 수 있도록 구현한 게 관계형 데이터베이스의 가장 큰 특징 중 하나입니다.
그 외 FK에서 알아야 하는 특징은 2개 정도 더 있습니다.
- FK는 반드시 다른 테이블의 PK일 필요는 없기에 자신의 PK를 FK로 참조가 가능하므로, 이를 이용하여 User 간 팔로우, 팔로워 등을 구현할 때에도 사용될 수 있습니다.
- FK는 PK와 달리 NULL을 허용할 수 있습니다. 이게 튜플의 식별자가 아니기 때문이며, 단순히 관계를 갖는 여부에 따라 데이터를 추가하고 말고를 설정하는 속성이기 때문입니다. 물론, not null로 운영할수도 있으니, 이는 설계 단계에서 자율적으로 정책 설정을 하면 됩니다.
물론, 실무에서는 데이터 규모가 상당히 크고, 그 관계가 매우 복잡하다보니 FK 설정으로 인한 무결성 제약조건을 관리하는 것이 불편하여 의도적으로 FK를 사용하지 않는 경우도 있다고 합니다. 이는 관리의 편의성을 바탕으로 서비스 설계 단계에서 고려해볼 수 있는 사안이지만, 성능적인 측면에서는 FK를 적절하게 사용하는 게 일반적인 경우에서는 더욱 좋기 때문에 장단을 고려하여 적절한 설계를 하는 것이 우리 개발자들의 몫인 것으로 보입니다.
무결성 제약조건
key를 이용하여 데이터베이스에 저장된 데이터의 일관성과 정확성을 지키기 위해 지켜야 하는 조건들을 의미합니다. 당연히 지켜져야 하는 내용이고, 이런 조건이 있는 이유는 각 키의 목적을 이해하면 모두 자명한 내용이라 간단하게만 정리하고 넘어가겠습니다.
- 도메인 무결성 제약조건
- 테이블에 저장되는 각 튜플이 갖는 각 속성값은 테이블 칼럼에 지정된 값만 가져야 한다는 조건이다.
- 도메인 무결성을 체크하기 위해 각 데이터의 data type, null 여부, 기본값 등을 체크한다.
- 만약 Users(id, age) 이라는 테이블이 있고, age 속성에 대하여 int, not null 조건이 매겨져 있다면 (1) 정수형 외에 문자열과 같은 데이터가 입력되지는 않았는지, (2) null이 입력되지는 않았는지 등을 체크한다.
- 개체 무결성 제약조건
- 모든 테이블은 pk를 가져야 하며, 지정된 기본키가 유니크한 값이며, NULL 값을 가져서는 안 된다는 조건이다.
- 기본키 제약조건이라고도 한다.
- 만약 Users(id, age) 테이블에서 id 값을 null로 입력하면 개체 무결성 제약조건이 위배되어 에러가 발생한다. 참고로, pk 설정시 unique 설정은 기본값으로 들어간다.
- 참조 무결성 제약조건
- 참조하는 테이블(자식 테이블)의 FK가 참조받는 테이블(부모 테이블)의 PK여야 한다.
- (당연하지만) FK에 입력되는 값은 참조 PK의 도메인 무결성을 준수해야 한다.
- 부모 테이블에서 참조되는 튜플의 PK는 자식 테이블이 존재하는 한 삭제되거나 수정될 수 없다.
- 참조에 NULL pointing이 되지 않도록 막는 조건이라고 이해하면 된다.
관계 데이터 모델 (ERD)

ERD(Entity-Relationship Diagram)는 데이터 모델링을 할 때에 각 릴레이션의 관계성을 설정하는 논리적 설계 시 사용하는 양식을 의미합니다.

위에서 사각형이 우리가 지금까지 봤던 table(relation), 동그라미가 각 table이 같는 속성값들입니다.

그 중에서 밑 줄이 그어진 속성이 PK입니다.

그리고 남은 게 이제 다이아몬드 모양이죠? 저게 바로 관계성을 나타내는 겁니다. 연결된 라인의 개수가 2개인지 1개인지에 따라서도 필수인지 optional인지에 대한 정보를 나타내며, 1인지 n 또는 m인지는 1대1 관계인지, 1대다 관계인지 등을 나타내는데, 이는 논리적으로는 이해하기가 오히려 어려우므로 스키마 설계에서 다시 다루겠습니다. (미리 궁금하다면 링크 참고해주세용)
주목할 점은, ERD를 작성함으로써 관계성에 영어로 코멘트를 달아줌으로써 각 테이블이 어떤 의미의 관계성을 갖고 유기적으로 연결되어 있는지를 정의할 수 있다는 겁니다. 이 과정을 통해 스키마 작성시 더욱 명확하게 데이터 구조를 이해할 수 있게 됩니다. 더욱 명료하게 이해할수록 스키마 구조화가 더 효율적이고 정확하겠죠. 따라서 ERD를 구성해보는 것은 복잡한 데이터베이스 설계를 위해서는 가장 단순하면서도 효과적인 논리적 모델링 방법이라고 할 수 있겠습니다.
정규화
데이터베이스는 두 가지 이상의 정보가 한 릴레이션에 저장되어 있을 때 이상현상이 발생합니다. 따라서 이상현상을 방지하지 위해 릴레이션 내에 있는 중복 데이터를 분리하는 작업이 필요하고, 이를 "정규화(Normalization)"라고 합니다.
정규화 과정은 기본적으로 제 1 정규형, 제 2 정규형, 제 3 정규형, BCNF(Boyce Codd Normal Form), 제 4 정규형, 제 5 정규형까지 총 6가지가 있습니다. 이를 모두 수행해야만 이상현상이 해결되는 것은 아니고, 대부분의 이상현상은 제 3 정규형 또는 BCNF까지 수행하면 없어진다고 합니다. 따라서 제 4 정규형과 제 5 정규형에 대한 설명은 저보다 더 전문적인 분들의 설명이 적힌 링크로 대신하고, 그 전까지 간단하게 짚고 넘어가겠습니다.
제 1 정규형
릴레이션 내의 속성값이 atomic해야 한다는 규칙을 준수하는 형태입니다. 이는 사실 기본적인 처리로, 관계형 데이터베이스를 사용하기 위해 당연히 이뤄집니다. 다음 이미지를 봐 봅시다.

위 이미지를 보면 "STUD_PHONE" 속성값이 여러개 들어가 있는 걸 볼 수 있습니다. 관계형 데이터베이스에서는 각 속성에 하나의 값만 가질 수 있으므로 이를 하나씩 가질 수 있도록 수정해줘야 합니다.
단순하게 말해서, 관계형 데이터베이스의 가장 기본적인 특징인 하나의 칼럼에는 하나의 속성값만 들어갈 수 있다는 조건을 만족시키는 것이 제 1 정규화입니다.
제 2 정규형
모든 nonprime attributes가 pk에 대해 완전 함수 종속이면 제 2정규형입니다.
- 완전 함수 종속 : A와 B가 릴레이션 R의 속성이라고 할 때, A -> B 종속성이 성립할 때, B가 A의 속성 전체에 함수 종속하고 부분집합 속성에 함수 종속하지 않을 경우 완전 함수 종속이라고 합니다.
즉, 부분 함수 종속이 없는 형태의 테이블이여야 한다. 이는 도메인에 대한 이해를 바탕으로 이뤄집니다.
다음 예시를 보겠습니다.
STUD_NO COURSE_NO COURSE_FEE
1 C1 1000
2 C2 1500
1 C4 2000
4 C3 1000
4 C1 1000
2 C5 2000
출처 : geeksforgeeks
위 예시에서 COURSE FEE는 COURSE NO에만 종속적이며, 이를 부분 함수 종속이라고 합니다. 따라서 부분 함수 종속을 제거해주면 제 2 정규형이 됩니다.
****Table 1**** ****Table 2****
STUD_NO COURSE_NO COURSE_NO COURSE_FEE
1 C1 C1 1000
2 C2 C2 1500
1 C4 C3 1000
4 C3 C4 2000
4 C1 C5 2000
2 C5
출처 : geeksforgeeks
조금 더 복잡한 예시로는 다음 예시가 있습니다.
- EMP_PROJ(SSN, Pnumber, hours, ename, pname, plocation)은
- hours는 (ssn,pnumber)에 종속적
- ename은 ssn에만 종속적 (부분 함수 종속)
- pname, plocation은 pnumber에만 종속적 (부분 함수 종속)
- → 부분 함수 종속을 갖는 nonprime attribute를 별도 테이블로 분리해주면 됩니다.
단순하게 말해서, pk가 테이블을 구성하는 모든 속성에 대하여 식별자의 역할을 할 수 있도록 처리해주는 것이 제 2 정규화입니다.
제 3 정규형
제 2 정규형을 만족하면서, 어떤 nonprime attribute도 이행종속성(transitive dependency)이 없으면 제 3 정규형입니다.
즉, 모든 nonprime attribute가 릴레이션 R의 모든 키에 완전 함수 종속이면서, 모든 키에 이행종속성이 없어야 합니다.
- 이행종속성이란 PK가 아닌 다른 후보키에 의해서도 다른 속성의 값을 알 수 있는 경우를 의미합니다.
- 즉, 테이블 내의 모든 속성이 기본 키에만 의존하며, 다른 후보 키에 의존하지 않아야 "이행종속성이 없는 것"입니다.
- 예시를 들자면, LOTS(id, county_name, lot_number, area, price)라고 할 때, id를 보면 area가 결정되는데, area만 봐도 price를 알면 안됩니다. (이런게 이행 종속)
- ⇒ 이럴때에는 area와 price를 별도의 테이블로 분리하고, fk를 할당해줘서 join할 수 있게 해두면 됩니다. (제3정규화)
단순하게 말해서, PK가 아닌 다른 후보키에 의해서 다른 속성 데이터가 식별될 수 있는 경우에는 이를 분리해서 관리하는 것을 제 3 정규화라고 합니다.
BCNF
- R(A,B,C)가 있고, A, B가 PK라고 할 때, A,B,를 보면 C라고 판단할 수 있고, C를 볼 때 B가 B라고 판단할 수 있으면 3NF이지만 BCNF가 아닌 경우이다. C → B가 안되어야 BCNF입니다.
- 예시를 보면, TEACH(student, course, instructor) 테이블이 있고, 그 함수 종속성이 FD1: {student, course} → Instructor, FD2 : Instructor → course라고 할 때 (Instructor, student), (Instructor, course)로 쪼개야 BCNF를 만족합니다.
단순하게 말해서, 후보키가 아닌 속성으로 튜플이 식별될 수 있는 경우 이를 분리해서 관리하는 것을 BCNF(강한 제 3 정규형)이라고 합니다.
마무리
여기까지 Database에 대한 간단한 이해와, 설계 단계에서 고려해야 하는 KEY에 대한 지식, 그리고 ERD와 정규화에 대하여 이해해 봤습니다. 정규화는 과도하게 진행될 경우 JOIN연산을 너무 많이 수행해야 하므로 이상 현상만 피할 수 있게 적절히 하는 것이 중요합니다. 이를 고려하여 ERD를 잘 작성해서 DB를 모델링 한 뒤에 스키마를 제작하면 됩니다.
다음에는 DB 스키마를 한번 코드로 짜 보겠습니다. 감사합니다.
'CS-STUDY > 데이터베이스' 카테고리의 다른 글
| [MySQL/Snippet] 프로시저 생성 템플릿 (0) | 2024.03.13 |
|---|---|
| MySQL로 이해하는 데이터베이스 2 - 로컬 DB 스키마 구축 (0) | 2024.02.16 |
| Java Swing, JDBC를 활용한 데이터베이스 관리 프로그램 (0) | 2023.11.07 |
| [트러블슈팅] No suitable driver found for jdbc:mysql://${dbhost}:3306/${dbname} (0) | 2023.11.01 |
| [트러블슈팅] unknown database 'database이름' (0) | 2023.10.27 |


